【昇腾推理】GPUStack 一键运行大语言模型推理
2025年5月6日大约 2 分钟
前言
上期我们介绍了如何在昇腾环境下使用 vLLM 进行大语言模型的推理部署,但当前 vLLM 在昇腾环境下性能实在不理想。而本期将是使用 Llama.cpp 作为后端,使用 GPUStack 一键运行大模型的推理部署。若使用非容器环境,则除去 Llama.cpp,还可选择更为理想的华为 MindIE 框架进行部署。GPUStack 的本机安装官方仅支持 Llama.cpp,Docker 部署同时支持 MindIE 和 Llama.cpp。
相关信息
GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。
其支持多种 AI 模型、框架,对广泛的硬件平台都提供了支持,官方直接支持的加速环境包括:
并计划在未来的版本中支持以下加速框架:
本文中的硬软件环境与上期保持一致。
部署
基础环境与下载模型
参阅上一篇文章,唯一的区别在于我们无需使用 Conda 或其他虚拟环境,安装脚本自有配置。
安装 GPUStack
本文同样使用 AutoDL 实例进行部署,因此仅演示 本地安装。
# 在 AutoDL 实例上,你需要先自行安装 sudo 和 lsof
# apt-get install -y sudo lsof
curl -sfL https://get.gpustack.ai | sh -s -一键脚本完成后,GPUStack 将自动运行为 systemd 服务,端口为 80。
若处于无 systemd 环境,可以尝试 /root/.local/bin/gpustack start 启动(默认安装位置),或 cat /etc/systemd/system/gpustack.service 检查 ExecStart 自行启动。
提示
使用 --port 9090 修改默认端口。
运行和管理模型
- 打开浏览器,访问
http://<ip>:<port>,即可看到 GPUStack 的图形界面。默认情况下端口号是80,AutoDL 实例可以使用 SSH 隧道转发。 GPUStack 将会自动纳管本机的所有 NPU,本文不涉及多节点部署,多节点请自行参阅文档。
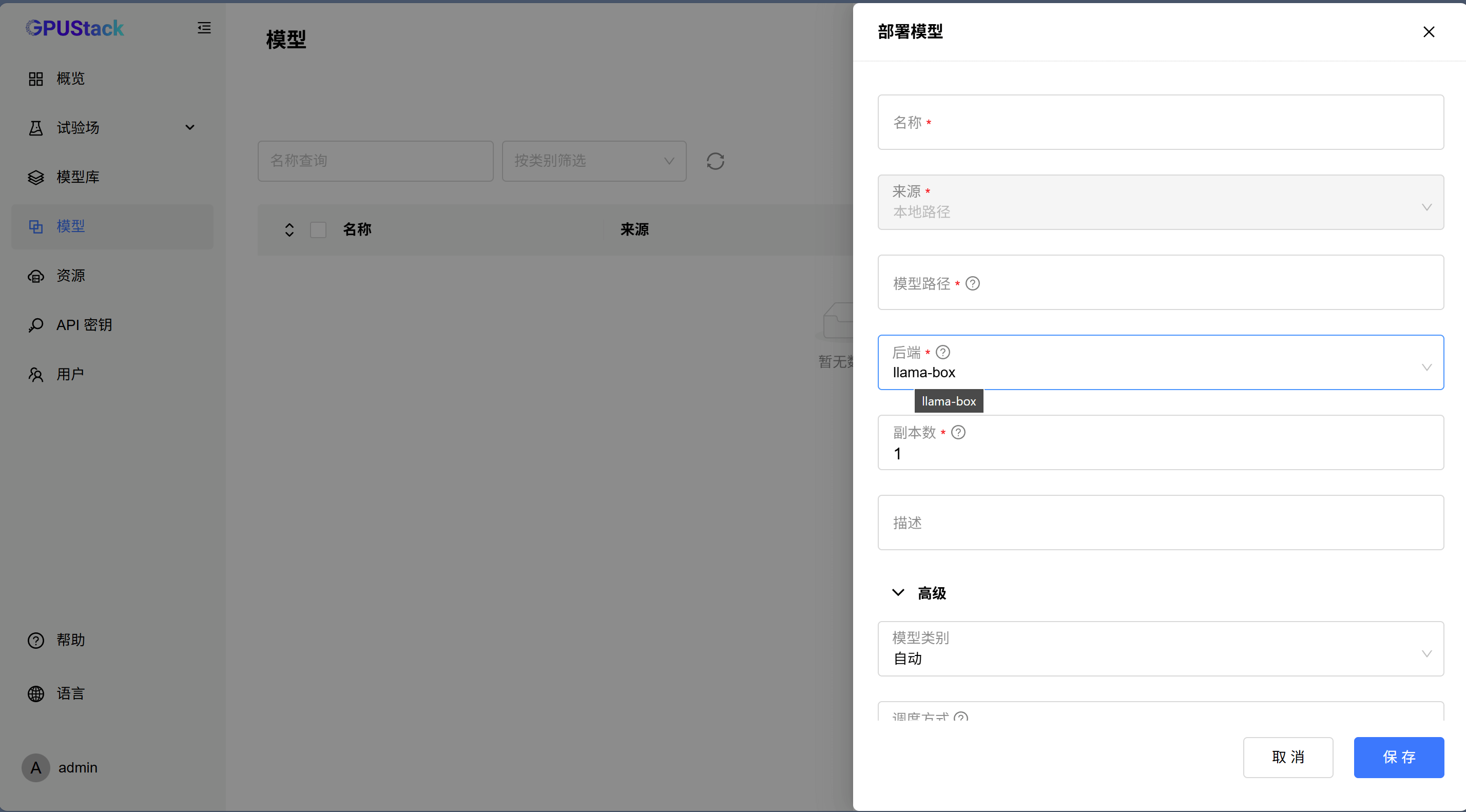
- 图形界面,不多做解释。参阅官方文档。注意,脚本安装在昇腾环境下仅支持 Llama Box 后端(一个封装的 Llama.cpp 和 Stable Diff),只能使用 GGUF 模型。
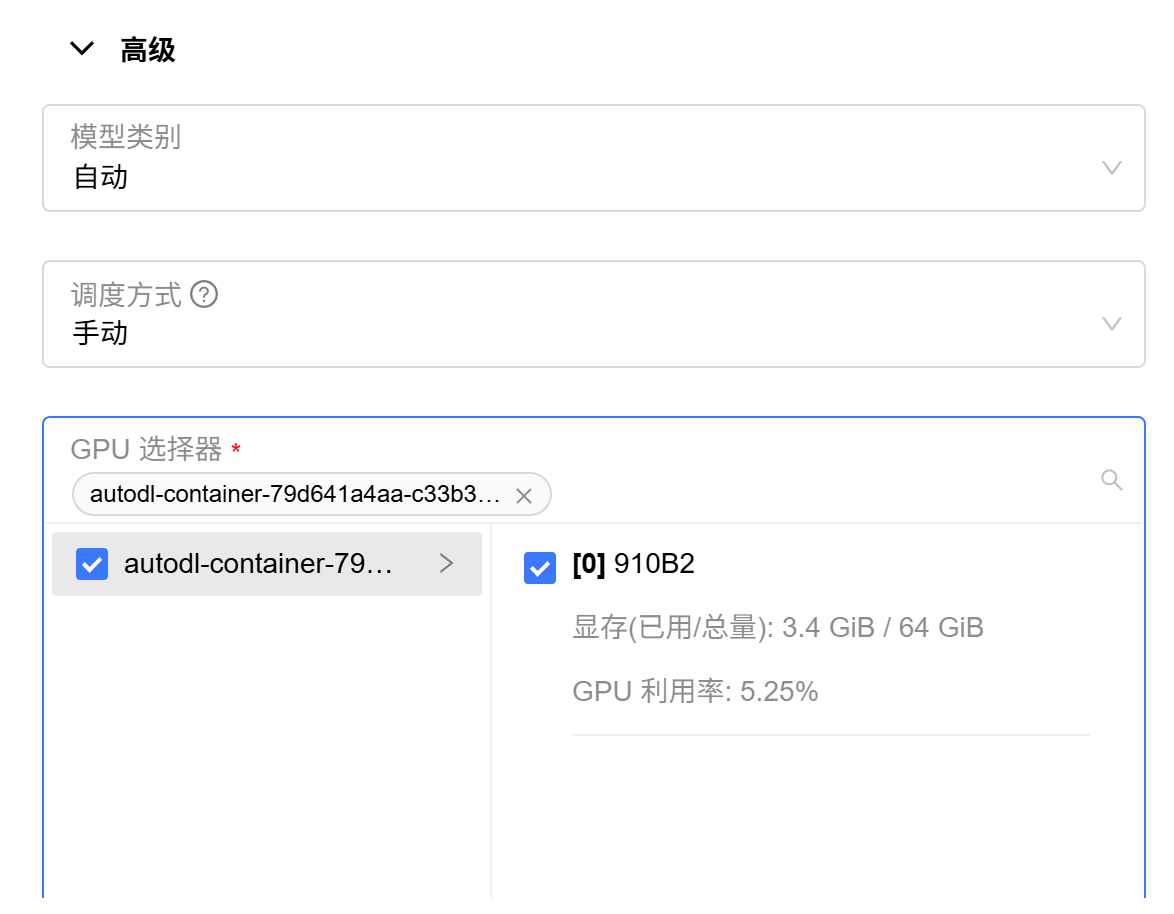
多 NPU 环境下需要使用手动指定模式,自动模式下多卡有问题,模型只能分到一张卡去。